如何 debug hive 源码,知其然知其所以然 |
您所在的位置:网站首页 › hive 开源客户端 › 如何 debug hive 源码,知其然知其所以然 |
如何 debug hive 源码,知其然知其所以然
|
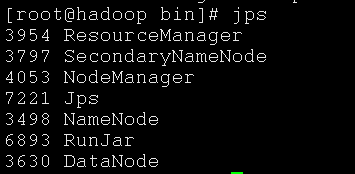
最近在出差,客户现场的 HiveServer 在很长时间内不可用,查看 CM 的监控发现,HiveServer 的内存在某一时刻暴涨,同时 JVM 开始 GC,每次 GC 长达 1 分钟,导致很长时间内,整个 HiveServer 不可用。 查看 HiveServer 日志发现,在那个内存暴涨的时间点,执行了一个 select count(1) from table 的 SQL,这个表有 2 万多分区,而且执行了很多次。 但是我始终无法解释,这样简单的 SQL 执行过程是什么,MapReduce 的什么阶段产生的什么对象占用了 HiveServer 的内存。 (导致被客户鄙视了,囧!) 这个问题其实也很好解决,两条路可以齐头并进: 一条路是把 HiveServer 那个时候的内存 dump 下来,分析一下里面究竟是什么东西;但这样无法看到具体执行流程是什么; 第二条路是下载 Hive 源码,直接 Debug 执行过程,弄清楚了之后,就可以解释中间的过程了。本文正是为 debug hive 源码准备的环境。 一、服务器环境准备我是用的 virtual box,centos 7 配置 hosts 安装必要的包: yum install -y which dos2unix 二、Hadoop Standalone 环境搭建下载一个 hadoop 发布包,地址是: https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/ 下载这个文件 hadoop-2.7.7.tar.gz上传到服务器,并解压缩到本地,我的目录是 /my2/hadoop 配置环境变量 vi /etc/profile追加 JAVA_HOME=/usr/local/jdk1.8.0_131 HADOOP_HOME=/my2/hadoop export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH export PATH刷新环境变量 source /etc/profile修改配置文件 (1)修改 etc/hadoop/hadoop-env.sh 文件 java 路径为上文构建 jdk 镜像中,Dockerfile 中写的路径 export JAVA_HOME=/usr/local/jdk1.8(2)修改 etc/hadoop/core-site.xml 文件 这里有个写死的项是主机名,我的是 hadoop001,修改成你自己的 fs.defaultFS hdfs://hadoop001:9000 hadoop.tmp.dir /usr/local/hadoop/tmp fs.trash.interval 1440(3)修改 etc/hadoop/hdfs-site.xml 文件 dfs.replication 1 dfs.permissions false(4)修改 etc/hadoop/yarn-site.xml 文件 yarn.nodemanager.aux-services mapreduce_shuffle yarn.log-aggregation-enable true(5)修改 etc/hadoop/mapred-site.xml.template 文件 重命名为 mapred-site.xml ,内容修改如下: mapreduce.framework.name yarn启动 hadoop 格式化 hdfs chmod -R 775 /my2/hadoop/* /my2/hadoop/bin/hdfs namenode -format启动 standalone 模式 /my2/hadoop/sbin/start-all.sh查看是否启动成功 jps
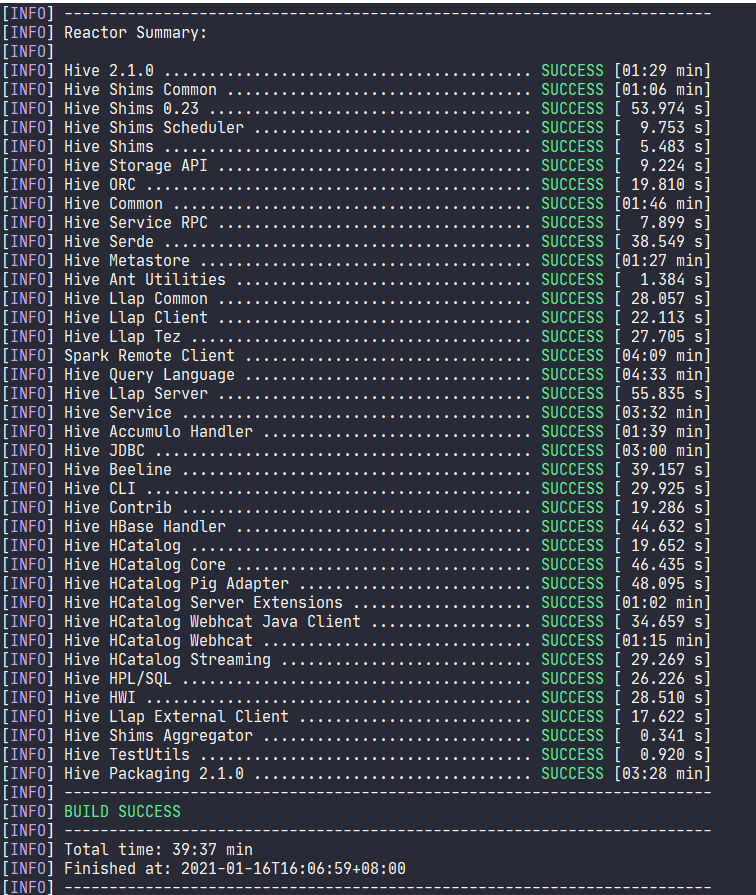
从 gitee 上 clone Hive 的代码 https://gitee.com/apache/hive 注意克隆之前一定要设置一下 git 换行符是否自动转换的 表示检出时 (clone),不自动转换为 crlf (windows)格式,以免最终打出来的包,脚本的格式都是 windows 格式的,无法运行。 git config --global core.autocrlf inputclone 到本地 git clone [email protected]:apache/hive.git切换到 2.1.0 分支 git checkout rel/release-2.1.0本地需要先编译一下整个工程,因为有些代码是用 antlr 自动生成的,编译之后,会产生对应的类。 这里必须指定 profile 为 hadoop-2 来支持 hadoop 2.x 版本 mvn clean package -Phadoop-2 -DskipTests -Pdist
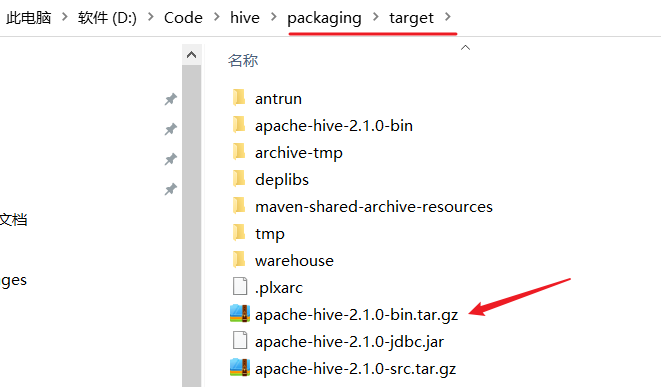
编译完之后,在 packaging 包中会生成一个二进制包,这个包可以在服务器上运行的
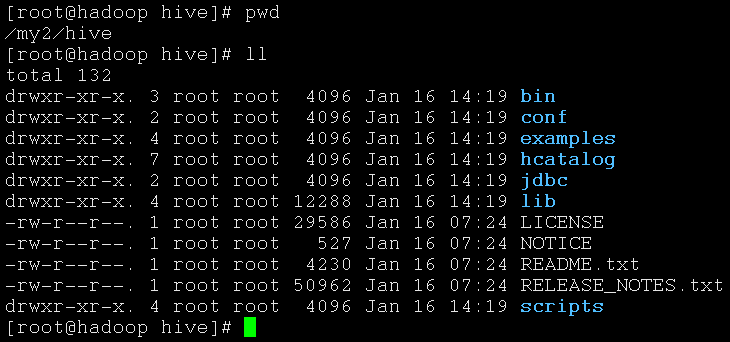
上传包并且解压缩,重命名解压缩后的目录为 hive
使用 docker 启动 mysql (使用 Docker 比较方便,你也可以使用你自己的 Mysql) docker run -d -it --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=debezium -e MYSQL_USER=mysqluser -e MYSQL_PASSWORD=mysqlpw debezium/example-mysql配置 hive-site.xml cd /my2/hive/conf cp hive-default.xml.template hive-site.xml vi hive-site.xml打开发现里面每一行都有一个 ^M 字符,这是 windows 换行符导致的,使用 dos2unix 替换即可 dos2unix hive-site.xml编辑 hive-site.xml vi hive-site.xml按 Esc,输入 /Connection (搜索 Connection),把搜索到的这几个 key 的值,替换成下面的 javax.jdo.option.ConnectionUserName root javax.jdo.option.ConnectionPassword debezium javax.jdo.option.ConnectionURL jdbc:mysql://192.168.56.10:3306/hive?createDatabaseIfNotExist=true;useSSL=false javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver复制 mysql 驱动到 hive 的 lib 目录下 初始化 metastore 的数据库 /my2/hive/bin/schematool -dbType mysql -initSchema接着 vi hive-site.xml,搜索 /user.name 把 {system:java.io.tmpdir} 改成 /home/hadoop/hive/tmp/ 把 {system:user.name} 改成 {user.name}启动 Hive 命令行即可 搜索 Connection 五、导入到 Idea 中 Debug然后把源码导入 IDEA 中,等待 IDEA 完成。 这里的 Debug 很简单,我们在服务器上远程 Debug。 首先在服务器上执行 hive --debug
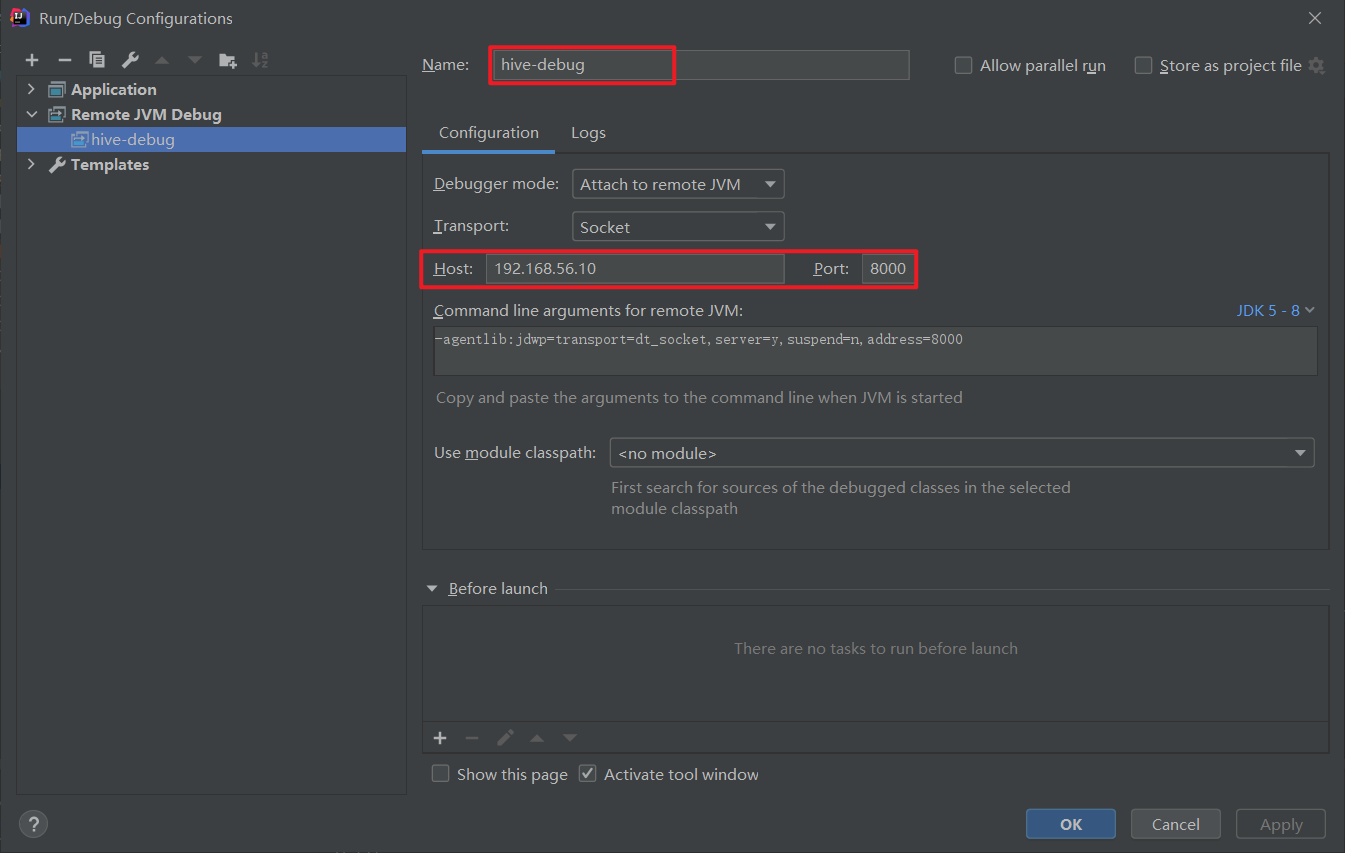
服务器显示在本机的 8000 端口等待连接 然后我们在 Idea 中配置一个远程 debug
点击 Debug 按钮,就可以 Debug了。 主要是 Debug 一下 CLIDriver 的 main 方法,里面有一个 run 方法
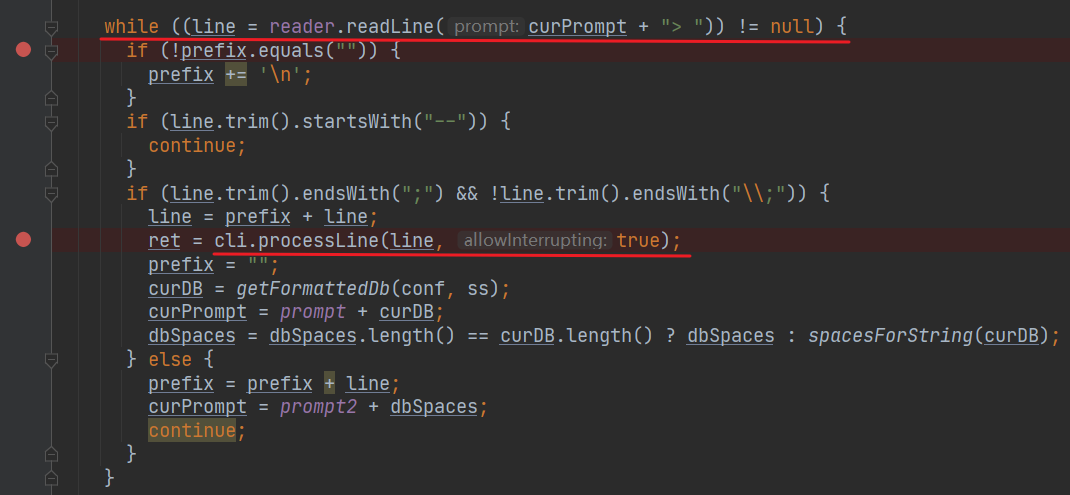
追踪到后面的源码,可以发现一直在等待用户的输入,每次输入之后,都会用 processLine 方法处理
processLine 也就是 Hive 执行 SQL 主要逻辑了,熟读这块代码,便可看到 Hive 的核心逻辑。 下次我们再探讨。 |


【本文地址】
今日新闻 |
推荐新闻 |